

Partitioning and bucketing in Spark
Under The Hood 3 - This isn't a casino, so stop shuffling!

Do you organize your clothes by color or by occasion? That's where the difference between partitioning and bucketing lies. Both are useful but in different contexts.

But first off, what do we want to avoid? Why is this necessary?
In the first Under the Hood post, we discussed how parquet files match with distributed compute workflows. A large number of files could be in the same folder and compose the same dataset.
Parquet files make navigating this data easier by enabling built-in statistics and metadata. However, if I only need to access a subset of data, I still need to iterate through the folder, reading each file to find what I want.
This seems simple for human reasoning but gets way more complex when we talk about distributing potentially hundreds of files to tens of nodes inside a cluster.
In data engineering terms, this is a shuffle-prone operation that can ruin your performance if you don't take the necessary precautions.
What's shuffling?
When a Spark cluster moves files between its nodes, it's called a shuffle. This happens when trigger transformations such as orderBy, groupBy, join, etc.
These operations require shuffling because the cluster needs to compare values in order to sort and group.
The rationale for ordering dates is something like this:
Node_1:
2024-01-01 -> 2024-05-31
Node_2:
2024-06-01 -> 2024-12-31
Node_3:
2025-01-01 -> 2025-05-31Shuffling is a computationally expensive operation because it involves two different orders of complexity.
There's a physical order composing the stream of data being transported through the network. There's also a logical order: the data being processed by different algorithms.
A computationally efficient Spark process minimizes shuffling.
We'll discuss two organization techniques that act in the physical order and make processing easier.
Partitioning
If you have ever delved inside an S3 bucket, you probably have seen a folder with several subfolders, each indicating a possible value in its name.
Something like this:
s3://adventure-works-sales/table_is_root/
├── year=2023/
├── month=01/
├── month=02/
├── ...
├── year=2024/
├── month=01/
├── month=02/
├── ...
├── year=2025/
├── month=01/
├── month=02/
├── ...This is a partitioning scheme. In each subfolder, files share a common value for the column expressed in the directory name.
This is done at writing time. A Spark process divides data by the desired column(s) and stores them hierarchically in folders and subfolders.
Obviously, having data separated and labeled like this makes for a good way of reading, processing and shuffling less data.
And which columns should we choose to partition data by?
Even distribution: pick the columns that divide data evenly per partition; avoid partitions with vastly different volumes.
Useful downstream: pick the columns most used to filter data; this saves time in reading and processing.
Good cardinality: high cardinality means a high number of unique values. You want to tread lightly; avoid having partitions with many small files. Don't partition by
IDbecause you'd have a ton of partitions with few rows. Partition by common grouping categories, likedepartment, season, dates,etc.Small number: Don't pick too many columns, or you'll have performance issues due to reading many partitions. Aim for 1 or 2 columns.
Bucketing
Bucketing is not a common organizational strategy, since it's relatively new, but it's very handy in workflows with wide operations or operations that involve shuffling.
(It's wide because you use many nodes.)
The logic of bucketing is as follows:
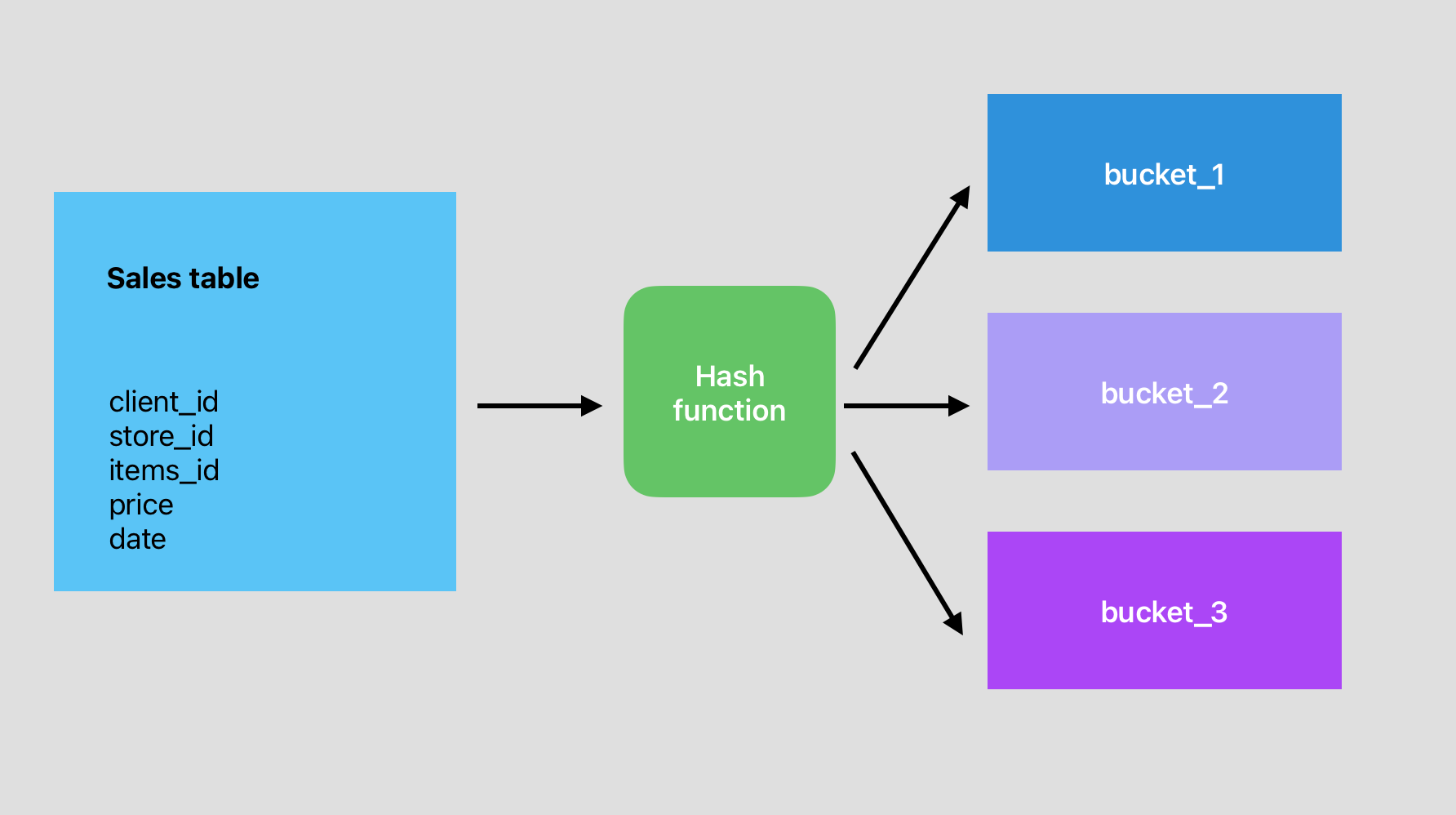
You have a starting table that is split in different buckets by a hashing function. This function tracks where each value is stored for a set of columns.
Let's say you want to join this sales table with a clients table and then perform some grouping operations by the client_id key.
Instead of two expensive shuffles (joining and grouping), you'll jump straight to your transformations.
And how do you bucket your table? At write time.
(
df.write
.bucketBy(8, 'column')
.sortBy('value')
.saveAsTable('df_bucketed', format='parquet')
)Writing with the bucketBy() param creates parquet files with this format:
├── part-00000-{uuid}.parquet # Bucket 0
├── part-00001-{uuid}.parquet # Bucket 1
...
├── part-00008-{uuid}.parquet # Bucket 8The parquet file is broken down into:
part= Spark partition file00000= Bucket number (0-8 in your case){uuid}= A unique identifier for that specific write operation.parquet= The file format
Please note that bucketing is not always necessary. If your downstream processes don't apply shuffle-prone transformations, this operation may not be needed.
Putting it all together
At write time you can combine partitioning and bucketing to create a performant table for your downstream processes.
In Spark SQL, you'd have something like this:
spark.sql("""
CREATE TABLE sales_data
PARTITIONED BY (year, month)
CLUSTERED BY (customer_id) INTO 64 BUCKETS
STORED AS PARQUET
""")
In S3, this would create a file layout like this:
s3://adventure-works/sales_data/
├── year=2024/
│ ├── month=01/
│ │ ├── part-00000-{uuid}.parquet # Bucket 0
│ │ ├── part-00001-{uuid}.parquet # Bucket 1
│ │ ├── ...
│ │ └── part-00063-{uuid}.parquet # Bucket 63
│ ├── month=02/
│ │ ├── part-00000-{uuid}.parquet
│ │ └── ...
├── year=2025/
│ ├── month=01/
│ │ ├── part-00000-{uuid}.parquet
│ │ └── ...You'll note, however, that you can have a varying number of buckets. How to choose the best number for your use-case? I'll talk about it in another Under The Hood.